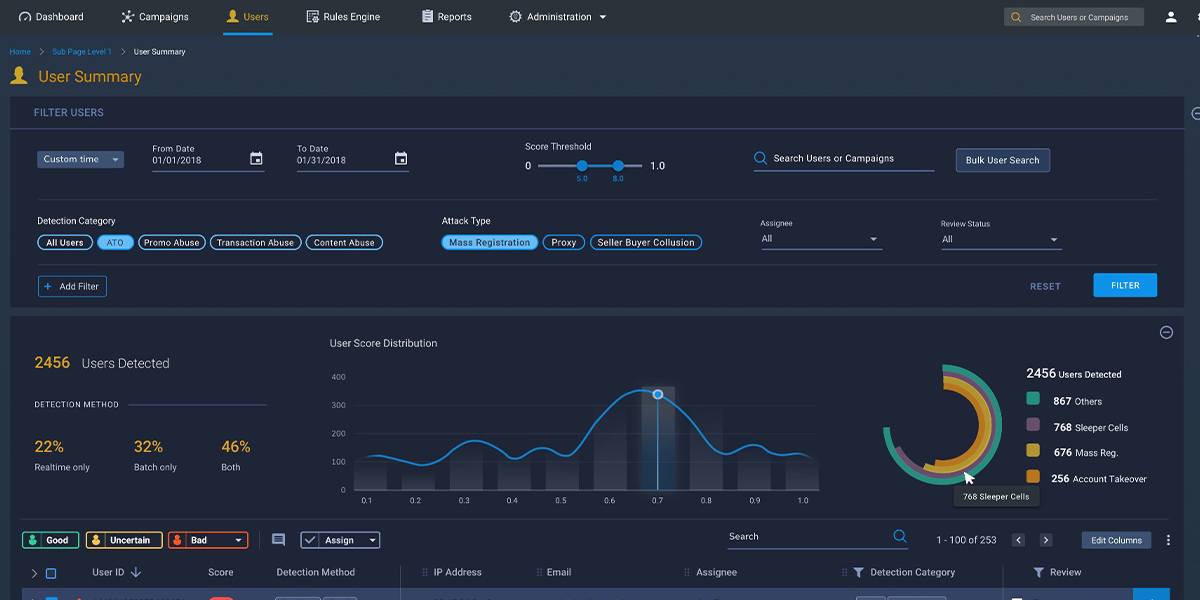
A three-part series focusing on fraud modeling: pre-modeling, modeling, and post-modeling.
The process of creating a successful product begins with acknowledging a negative—something is missing. There is a problem, and it requires a solution. When it comes to fraud management, problems are often severe, with billions of dollars at stake. dCube is a product that solves a problem, and clients that use it have a superpower—the ability to detect unknown fraud before it happens. The technology behind dCube is transformational and demonstrates how artificial intelligence gives the advantage back to those fighting fraud.
The power of machine learning modeling
Empowering organizations to adapt to fast-emerging fraud with agility and speed is the primary purpose of dCube, and enabling teams to use advanced modeling capabilities is central to dCube’s success in enabling organizations to proactively defeat known and unknown attacks. Sophisticated machine learning models are one of our most powerful weapons in the fight against fraud, and building these models is a complex task that requires advanced data skills and extensive fraud domain knowledge.
We can understand fraud modeling by looking at three phases of the process: Pre-Modeling, Modeling, and Post-Modeling. This post, the first of three, will focus on Pre-Modeling.
Data management challenges
Data scientists and risk teams too often spend their time consolidating data from fragmented sources and then cleaning and organizing that data, as opposed to being able to focus on building models optimized for advanced fraud detection. Moreover, poor initial data quality results in slow model building because of the time lost to unearthing and repairing data quality issues. Worst of all, the models won’t perform well if the data quality is poor.
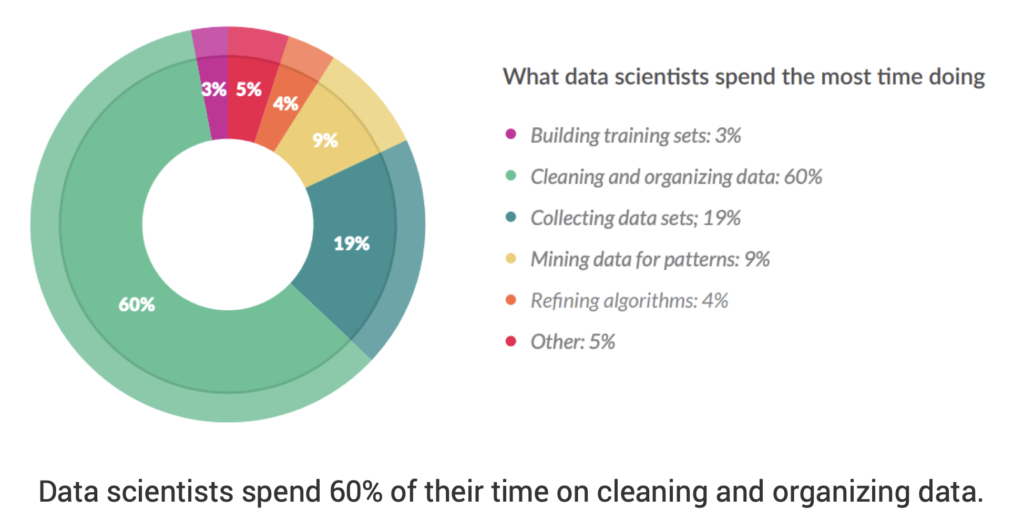
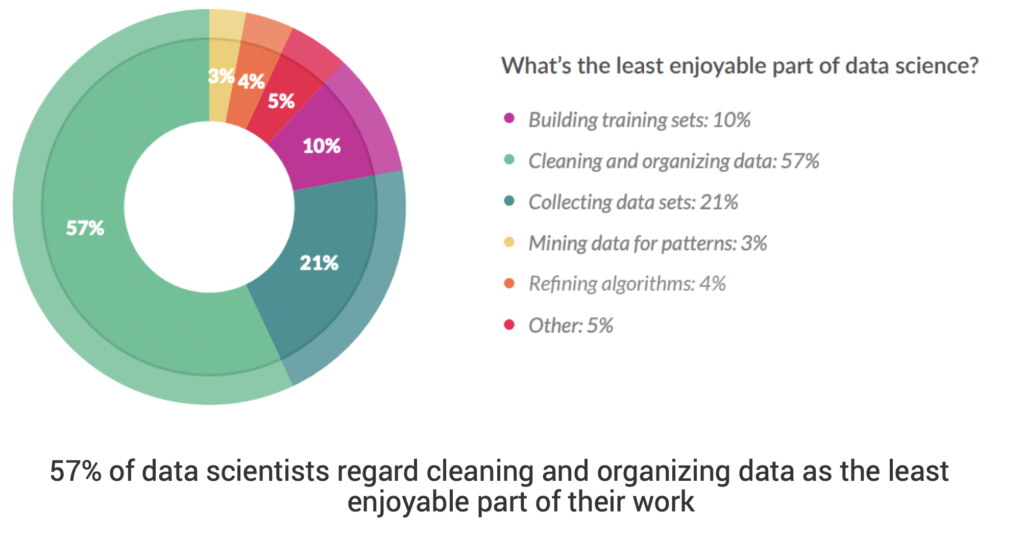
Feature engineering challenges
Once data is adequately prepared, feature engineering can commence, but additional challenges remain. Features engineering requires extensive experience developing fraud models, as well as a deep understanding of an organization’s business goals and requirements. But this level of knowledge and experience is hard to come by. Data scientists bring a wide array of critical skills to the table, but their experience may not be fraud-specific, and they may not always have the domain expertise needed to derive and determine which features are most important for fraud detection, and which features work best for different fraud use cases: ATO, Application fraud, AML, and more. Creating custom features is complicated, and teams will often require support from their IT department, making the whole feature engineering process all the more time-consuming and painful.
Creating a new solution with dCube
In building dCube, we’ve created a comprehensive fraud management solution that combines transformational AI-powered technology with a streamlined workflow to enable large enterprises to proactively thwart both known and unknown fraud. It’s an end-to-end fraud solution loaded with capabilities that include: data management, feature engineering, model development and deployment, analytics, and case management.
Solving pre-modeling challenges
dCube solves pre-modeling challenges in a number of innovative ways:
Data Management
- Automatically merge data from multiple data sources, and either from local or cloud.
- Map input data fields to known and recommended fields to enable automated data validation and feature derivation.
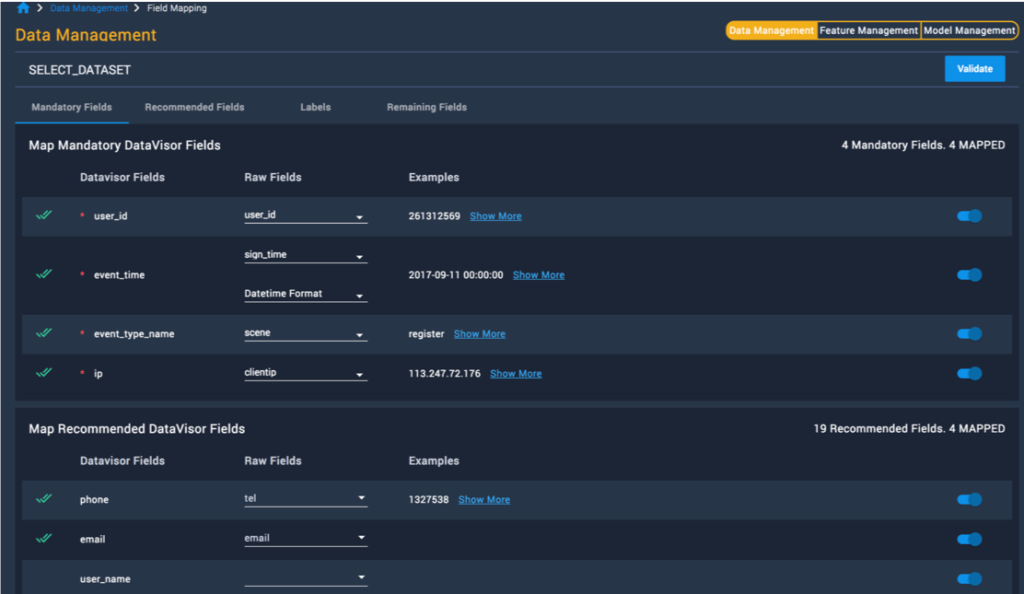
- Use field distribution analysis to gain a quick overview and understanding of how your data looks before modeling (e.g., event count, location distribution, and more).
- Validate data quality and format issues in advance by scanning automatically for potential issues and creating validation report with stats, alerts, and warnings.
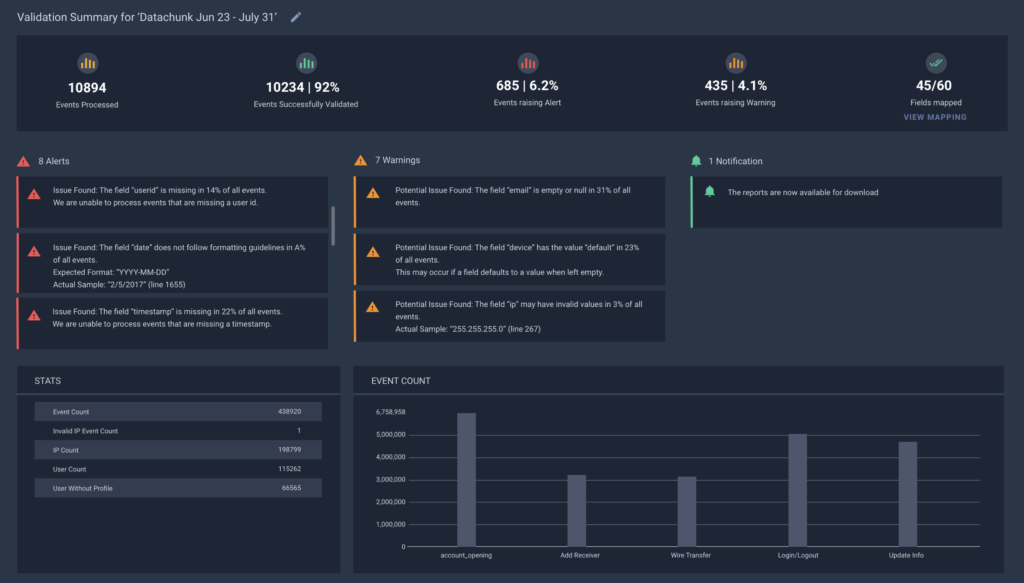
- Systematically organize all data sets and track status.
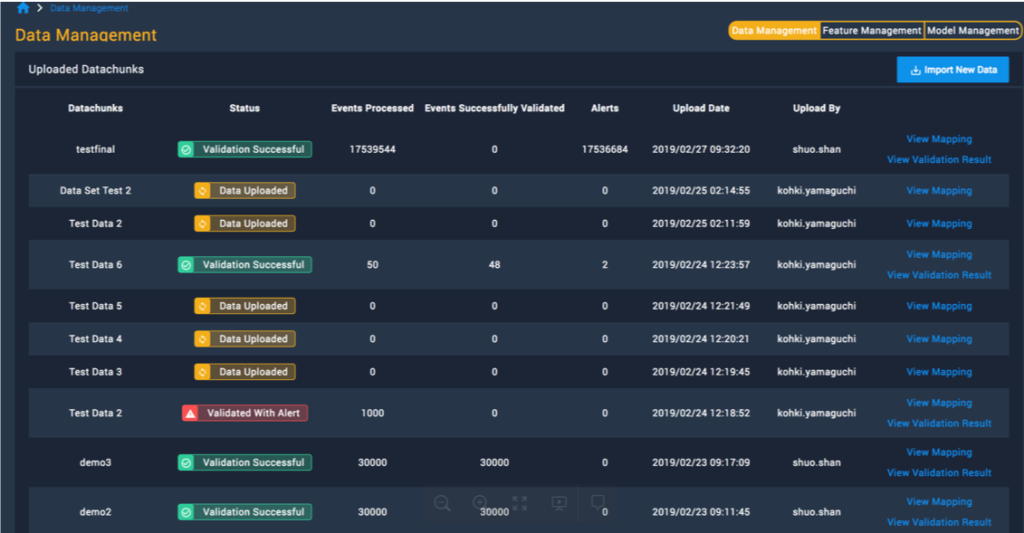
Feature Engineering
- Leverage the most sophisticated and advanced fraud features, including hundreds of pre-built fraud features: IP, email, user agent, username, location, device, and more.
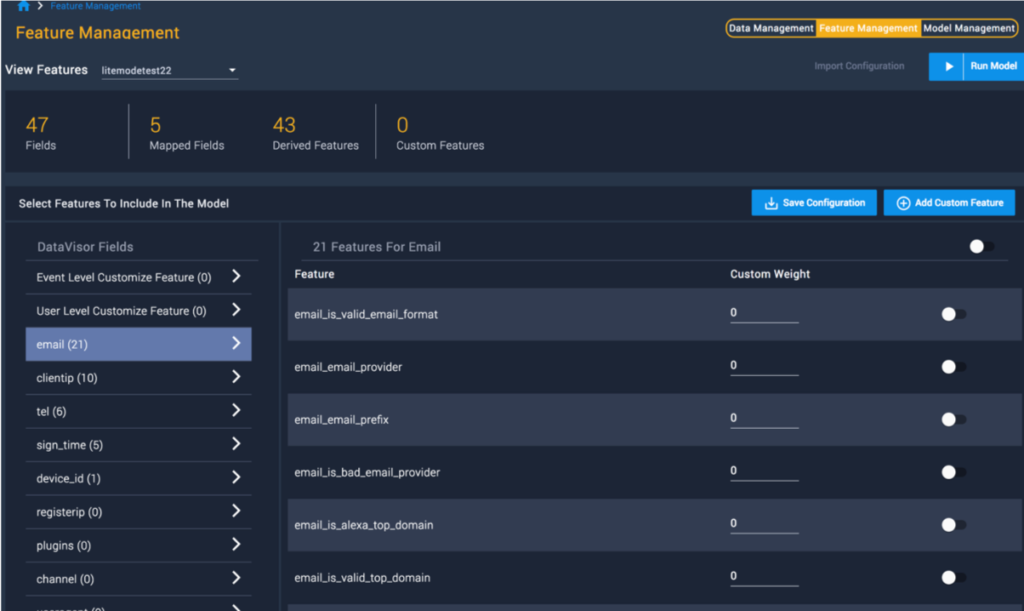
- Engineer custom features with just a few clicks, and without requiring additional support from the IT team. Use dCube to create attribute features, velocity features, complex logic, or even a combination of multiple simple logic features together with velocity features.

- Benefit from automatically recommended features and weights optimized for different use cases (ATO, Application fraud, AML) and powered by DataVisor domain expertise. Accept recommendations, or override weights with a custom value. This flexibility gives data scientists and fraud analysts the ability to apply proprietary knowledge of organization-specific fraud; this, in turn, serves to further enhance model performance.
Boosting efficiency and focusing on what matters
dCube’s powerful array of capabilities combine to put real power in the hands of users, enabling teams to significantly accelerate the pre-modeling process. Critically, data scientists are able to focus on what really matters—building high-performance models—instead of cleaning up poor quality data. To use dCube is to experience efficient featuring engineering powered by unrivaled domain expertise, and to enjoy the flexibility to engineer complex customer features effortlessly, without the support of additional stakeholders. With dCube, teams no longer have to build and test everything from scratch. Instead, dCube establishes an excellent baseline of weight recommendations optimized for different use cases. Stay tuned for the second article in this series, in which we highlight modeling, with a focus on model building, tuning, and deployment.